V.1.8 - Dernière mise à jour : 10/10/2008
Groupes de techniques permettant :
- de traiter simultanément un ensemble nombreux de variables ;
- de ne pas faire d'hypothèses contraignantes a priori ;
- de faire ressortir une structure latente, profonde, non immédiatement décelable ;
- de simplifier et d'organiser l'information.
- On distingue deux grands groupes en fonction de leur finalité.
Ceux qui servent plutôt à :
- former des groupes de variables et à hiérarchiser l'information ;
=> analyse factorielle*
- former des groupes d'individus ;
=> classifications multivariées*
- L'ensemble de ces méthodes est adapté à l'analyse de l'organisation de l'espace
- Ces méthodes nécessitent :
- une organisation de l'information géographique en matrice d'information spatiale* ;
- une réflexion sur le choix des unités spatiales élémentaires* (nature et échelle du problème traité) ;
- une réflexion sur le choix des variables* (homogénéité de l'information).
- Ces méthodes ne supposent pas :
- d'hypothèses sur la distribution statistique des variables ;
- ni de connaissances de modèles probabilistes particuliers ;
contrairement aux méthodes classiques de la statistique.
- Quelles que soient les dimensions de la matrice d'information :
- Ces méthodes descriptives servent à :
- affiner les descriptions ;
- éliminer les "bruits" qui parasitent notre perception ;
- révéler les associations et les interactions ;
- éliminer la part d'arbitraire des comparaisons de cartes.
Donc à réaliser des typologies*
C'est à dire, constituer des groupes d'individus plus semblables entre eux qu'ils ne le sont avec les autres (au regard des variables étudiées).
- Une analyse factorielle sert à :
- résumer ;
- hiérarchiser ;
l'information contenue dans un tableau de :
- n lignes (les individus) ;
- p colonne (les variables).
Les n individus sont décrits par un nuage de p variables.
- L'information représentée par ce nuage,
c'est la dispersion des n points.
- Produire un résumé de cette information c'est
projeter ces points dans un espace de dimension inférieure à p.
- Les axes de ce sous-espace sont dits "axes factoriels*" ou "facteurs*".
- Le résumé est possible dans la mesure où
les variables ne sont pas totalement indépendantes
- Chaque variable "p" porte en elle :
- une part d'information originale ;
- une part d'information redondante avec les autres.
C'est cette part d'information redondante que l'on va regrouper dans le résumé factoriel.
- Chaque facteur est la combinaison linéaire des "p" variables.
A chaque variable est associé un coefficient "a".
Ce coefficient "a" est proportionnel à l'intensité qui lie la variable au facteur.
Ces facteurs, ou axes, rendent compte des associations entre les variables.
Leur nombre apparaît bien plus réduit que celui des variables d'origine.
Les facteurs sont hiérarchisés :
- le 1er axe concentre le maximum de l'information ;
- c'est l'axe de la plus grande dimension du nuage de points
- c'est le meilleur résumé dans un espace à une dimension
- mais il laisse des résidus (de l'information)
- le 2e axe concentre le maximum de l'information restante ;
- il est orthogonal au premier (par construction)
- c'est l'axe de la plus grande dimension résiduelle du nuage de points
- associé au 1er axe, c'est le meilleur résumé dans un espace à deux dimension
- mais il laisse aussi des résidus
- le 3e axe prend encore une part d'information moindre ;
- il est orthogonal au deux premiers (toujours par construction)
- ainsi de suite
Objectif principal : former et hiérarchiser des groupes de variables
- L'analyse en composantes principales (ACP)
C'est la technique la plus ancienne
- S'applique principalement aux tableaux de mesures*
=> variables quantitatives (données brutes, ratio, %, ...)
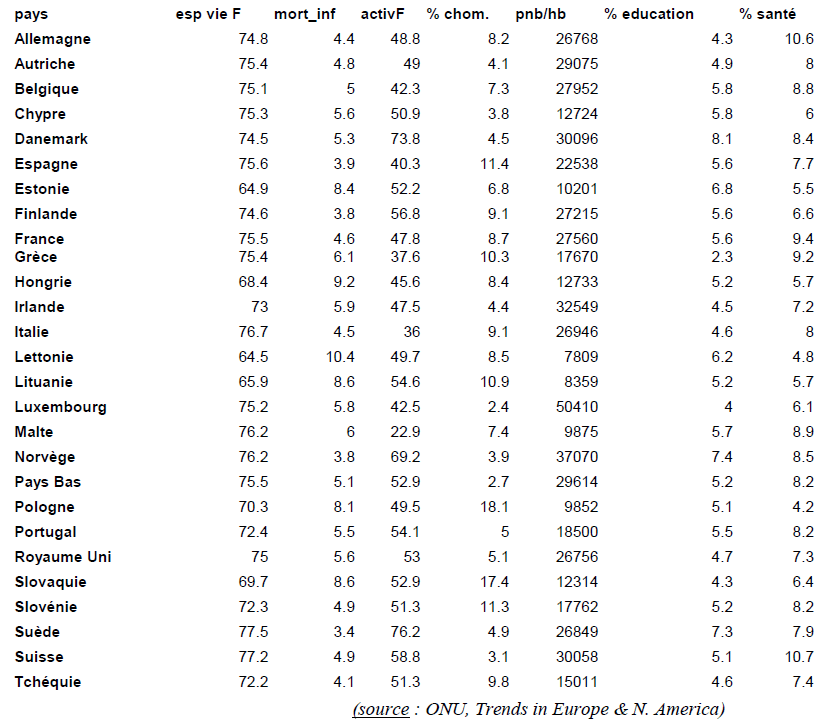
tab. 1 - Variables démographiques et économiques pour 27 pays européens (DUMOLARD 2005, tab. 2.2) => matrice d'information spatiale
- l'Analyse factorielle des correspondances (AFC)
- S'applique principalement aux tableaux de contingence*
=> variables quantitatives (données brutes sommables en lignes et en colonnes)
- Mais également aux tableaux disjonctifs complets*
=> variables qualitatives (nominales en présence / absence)
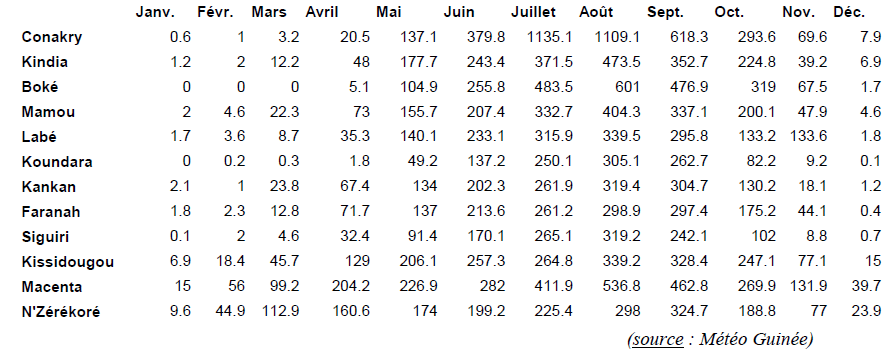
tab. 2 - Précipitations moyennes mensuelles de 12 villes guinéennes (DUMOLARD 2005, tab. 2.3) => matrice d'information spatio-chronologique
Objectif principal : former des groupes d'individus
- Les classifications ascendantes hiérarchiques (CAH)
Une des techniques les plus utilisées en géographie.
Permet :
- d'effectuer des typologies emboîtées ;
puis
- des cartographies.
- Les classifications autour de centres mobiles, type nuées dynamiques
- Méthodes utilisées sur de très grosses populations
- Permet de rechercher le nombre de classes optimales le plus stable (robuste)
repose sur un grand nombre d'itérations
- Les classifications à limites mobiles ou floues
- Quand les classes obtenues :
- ne sont pas disjointes ;
- reposent sur des probabilités d'appartenance...
Ces deux dernières ne seront pas abordées ici.
Les analyses factorielles et les techniques de classification sont complémentaires.
On sera donc amené à les utiliser conjointement.
Elles permettent de tester de nombreuses hypothèses,
mais n'ont aucun pouvoir explicatif !
- Quelles sont les étapes d'une analyse avec SPAD ?
Une base SPAD est un ensemble de données numériques au format SPAD
Le menu Base gère les opérations de création et d'édition des bases
- Pour créer une base SPAD
- Nouvelle base
à la main à l'aide de l'éditeur de base
- Importer
- tout fichier texte ASCII en alphanumérique* avec :
- individus* en lignes
- variables* en colonnes
- une table SAS (format XPORT)
- un fichier SPSS (*.sav)
- Pour modifier une base SPAD
- Un tableur permet de saisir ou modifier :
- les libellés de variables ou des modalités*
- un tableau de valeurs
- Le menu outil permet de créer de nouvelles variables par :
- recodage => mise en classes, croisement, opération, ...
- quantile* => pour mettre en classes d'effectifs égaux* des données continues*
- redressement* => pour créer et conserver une variable poids par ajustement à des distributions*
Une filière est une suite de méthodes statistiques cohérentes entres elles.
Toutes s'appliquent à la même base SPAD
- Paramétrage des méthodes de la filière
Depuis le menu Filière choisir :
- Filières prédéfinies
permet de créer une nouvelle filière utilisant une ou plusieurs méthodes statistiques cohérentes entre elles
fig. 1 - Exemple d'une filière prédéfinie - Analyse factorielle - Composantes principales
Sources : Document Cisia- Nouvelle filière
- ouverture d'une fenêtre Filière sans_nom qui ne contient, au départ, aucune méthode ;
- choisir une base en double cliquant sur l'icône base ;
- insérer une méthode
Menu Méthode + Insérer méthode (ou Ctrl + I)
- choisir une méthode
Menu Méthode + Choisir méthode (ou Ctrl + C)
- Paramétrage proprement dit de la méthode
Sur la figure n°1, la filière n'est pas exécutable
il faut d'abord paramétrer les méthodes
fig. 2 - Une méthode paramétrée est jaune
Sources : Document Cisia- pour paramétrer une méthode il faut aller dans :
Menu Méthode + Paramètres (ou Shift + F6)
ou double clique sur l'icône de la méthode
- effectuer les choix demandés dans la boîte de dialogue
- cliquer sur OK
fig. 3 - Exemple d'une filière paramétrée (les méthodes sont jaunes)
Sources : Document Cisia
- Enregistrement de la filière
Toute filière doit être enregistrer avant d'être exécuter
Menu Filière + Enregistrer filière sous ...
- Donner un nom à la filière pour la rappeler
- Exécution de la filière
Menu Filière + Exécuter filière (ou F5)
fig. 4 - Exemple d'une filière exécutée (apparition des icônes listages et écrans)
Sources : Document Cisia
- Consultation des résultats
En double cliquant sur l'icône listage ou sur l'icône écran
- Le tableau EXCEL est-il compatible avec SPAD ?
Exemple n°1 : Tableau 2.1 - Dix mesures relatives à la qualité de la vie dans 18 grandes métropoles américaines (Sources : M.V. JONES and M.J. FLEX, The quality of life in Washington D.C., The Urban Institute, Washington D.C, 1970. in SANDERS 1989, p. 57)
Ce fichier est au format EXCEL 5.0 et "pèse" 97 Ko.
Exemple n°2 : AMAT (J.-P.), GODARD (V.), HOTYAT (M.) - 2003 - Milieu, gestion, histoire et scénarios de reconstitution dans les sylvosystèmes touchés par les tempêtes de décembre 1999, GIP-ECOFOR, Min. agriculture, 115 p.
Ce fichier est au format texte tabulé et "pèse" 5 Ko.
Exemple n°3 : Tableau 4.1 - La structure pastorale éthiopienne par awrajas (en nombre de têtes), [Sources : EASTMAN (J.R.) - 1997 - 10. Database Workshop. in : IDRISI for Windows. Tutorial Exercises. Version 2.0. Worcester (MA, USA), Clark University, pp. 69-79 et traduction française GODARD, 2003]
Ce fichier est au format Excel (.xls) et "pèse" 51 Ko.
Ce tableau est le support d'un exercice détaillé sur le fiche guide 1.8 du cours de SIG.
L'import des données se fait comme expliqué sur la fiche mémo mem04dea.htm du cours de Master 2 recherche.
Exemple n°4 : Pauvreté sur la GulfCost
Ce fichier est au format Excel (.xls) et "pèse" 46 Ko.
- Sélectionner les données utiles dans la feuille "brut"
de A2 à K21
Pas de blancs ni de caractères spéciaux dans les intitulés de variables
- Les coller par Collage spécial du menu Edition
en A1 de la feuille "txt"
- Faire un Enregistre sous du menu Fichier
Le type de fichier doit être en :
Texte tabulé (*.txt)
L'enregistrer en :
D:\geo\Votre_Nom\villesus\ta1fm02d.txt
- Comment passer d'un tableau EXCEL à une base SPAD ?
- Lancer SPAD
- Modifier les répertoires par défaut
Menu Option + Paramètres généraux ...
Répertoires utilisés par défaut
pour les bases => D:\geo\Votre_Nom\villesus\
pour les modèles => D:\geo\Votre_Nom\villesus\
pour les filières => D:\geo\Votre_Nom\villesus\
la zone temporaire => D:\geo\Votre_Nom\temp
les importations => D:\geo\Votre_Nom\villesus\
Ne mettez pas d'accent (ou de caractère spéciaux) à dea ou ailleurs !
Importation fichier ASCII... du sous menu Importer du menu Base
Cliquer sur Nouveau
Entrer le nom de l'importation => Villes US
SPAD demande :
- de localiser le fichier ".txt"
sélectionner ta1fm02d.txt
- le format du fichier
- délimité
- séparateur tabulation
- décimale point
- de cocher :
- si la 1ère ligne contient la variable
- Utiliser les X premier caractères ....
valider en cochant Suivant
SPAD râle (version antérieure à la 5.5) car il y a un blanc après la variable INCO !
Retourner dans EXCEL enlever l'importun !!!
- de définir les variables en :
- Type
Cliquer sur Aide puis Description en format délimité des variables importées et enfin sur type (puis Pour choisir le type)
- Que doit-on mettre comme type pour villes ?
villes => choisir Identificateur
sous cette colonne se trouve le nom des individus
- Que doit-on mettre comme type pour INCO et les suivantes ?
INCO => choisir Continue
sous cette colonne se trouve les modalités prisent par chaque individu.
La zone de cases à cocher, juste en dessous de la liste des variables, permet, après une sélection multiple par les chiffres en gris, d'affecter le même Type à plusieurs variables.
- Libellé
- facultatif, remplace en 60 caractères maxi le titre dans la base
- Code Id.
- option pour les QCM ;
- pour recoder des variables (nominales ou alphabétiques) de même type.
- d'Exécuter l'importation
- enregistrement de la base au format ".sba"
- si l'importation se passe bien, consulter :
- les statistiques de la bases
- l'édition des résultats
- l'édition du compte-rendu qui signale toutes les anomalies lors de l'importation
- codes inattendus,
- variables transformées, ...
- si l'importation comporte des erreurs :
- la base n'est pas générée
- cliquer sur le bouton "Il y a des erreurs" qui édite le compte rendu ;
- corriger (!!!) puis relancer l'exécution.
- Enfin, cliquer sur OK, puis Fermer.
- Éditer une base
Menu Base + Editer base ... (ou Ctrl + T)
Notons que :
villesus\ta1fm02d.txt est devenu villesus\ta1fm02d.sba
- Trois tableaux apparaissent :
- les variables
- les individus
- les valeurs
Il est donc possible d'intervenir sur ces trois tableaux
- Créer une nouvelle filière
Menu Filière + Nouvelle Filière (ou Ctrl + N)
- Insertion d'une première méthode
Dans la fenêtre Filière 1 : ( sans nom)
- Choisir une base
Filière + Sélectionner base
D:\geo\Votre_Nom\villeus\ta1fm02d.sba
- Méthode + Insérer méthode (ou Ctrl + I)
- Méthode + Choisir méthode (ou Ctrl + C)
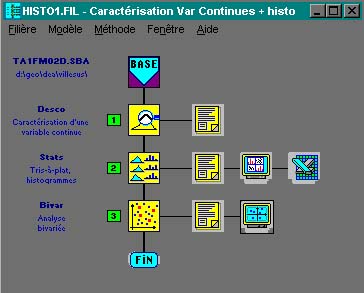
- Groupes de méthodes : Description statistique
- Méthode : Caractérisation d'une variable continue
[ou faire glisser, depuis la fenêtre des méthodes (cf. fig n°5) l'icône de "Caractérisation d'une variable continue" (la 2a) sur l'icône de la méthode, dans la fenêtre Filière 1 : ( sans nom)]
fig. 5 - La fenêtre des méthodes
Sources : Document Cisia- Méthode + Paramètres ... (ou Shift + F6)
pour choisir les variables à caractériser et caractérisantes
Onglet Variables
- Sélection des variables : continues à caractériser
=> toutes
- Sélection des variables : continues caractérisantes
=> toutes
- Insertion d'une deuxième méthode
Toujours dans la fenêtre Filière 1 : ( sans nom)
- Méthode + Insérer méthode (ou Ctrl + I)
- Méthode + Choisir méthode (ou Ctrl + C)
- Groupes de méthodes : Description statistique
- Méthode : Tris-à-plat, histogrammes
ou faire glisser l'icône de "Tris-à-plat, histogrammes" sur l'icône de la méthode
Attention "Tri-à-plat" est réservée aux variables qualitatives* (nominales*)
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Histogrammes - Discrétisation
Pour choisir les Variables
- Sélection des variables : Pour histogrammes/Statistiques sommaires
("Pour discrétisation" ne fonctionne pas sur des variables continues)
- Variables sélectionnées :
- => toutes
- Insertion d'une troisième méthode
Toujours dans la fenêtre Filière 1 : ( sans nom)
- Méthode + Insérer méthode (ou Ctrl + I)
- Méthode + Choisir méthode (ou Ctrl + C)
- Groupes de méthodes : Description statistique
- Méthode : Analyse bivariée
ou faire glisser l'icône de "Analyse bivariée" sur l'icône de la méthode
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Variables
Pour choisir les Variables AXES
- Variable 1 : UNEM
- Variable 2 : SUIC
Pour choisir les Variables de description
- Continues illustratives
- => toutes
- Enregistrement et exécution de la filière
- Filière + Enregistrer filière sous ...
D:\geo\Votre_Nom\ villesus\desco1.fil
Donner un titre "causant", car il apparaîtra sur le bandeau de la fenêtre
- Filière + Exécuter filière (ou F5)
Vous devez obtenir ça :
fig. 6 - La filière après exécution
- Double clique sur la galerie de graphiques
Pour choisir les Variables
- => toutes
Pour choisir la Galerie
- Lignes : 10
- Colonnes : 10
(il y a 10 variables, le pavage graphique fera 10*10 = 100 histogrammes !)
Agrandir la fenêtre si nécessaire !
- Information sur les individus
- Déplacez le pointeur sur lui !
- Dans la barre d'état
- le nom à gauche
- la valeur pour les deux variables à droite
- Information sur une cellule
- Double clique sur la cellule
On obtient par variable :
- moyenne
- écart-type
- nombre de valeurs manquantes
- coeff. de corrélation (r)
- coeff. de régression (a)
- ordonnée à l'origine (b)
du "y=ax+b" qui décrit la droite de régression
- Le balayage
Pour désigner des points que l'on veut localiser sur tous les graphiques
- Sélectionner le bouton balayage
(ou Menu Outils + Balayage)
- Sélectionner sur un graphique les points (villes) :
- Los Angeles
- San Francisco
(déjà isolés sur la variable SUICide)
Un clique bouton droit dans une zone balayée indique les individus présents
- Modifier la configuration du balayage
Menu Outils + Configuration du balayage
La fenêtre Couleur et habillage pour le balayage apparaît.
Modifier les paramètres
- Les histogrammes
Pour obtenir les "histogrammes" des variables de la galerie
- Sélectionner le bouton histogrammes
(ou Menu Outils + Histogramme)
La fenêtre Configuration de l'histogramme apparaît.
- Déterminer le nombre de barres
- Combien faut-il de barres ?
Si vous ne savez pas comment le déterminer, cliquez là !
- Sélectionner le bouton Histogrammes et courbes de densité normale
- Sélectionner le bouton Valeurs
Cliquer sur OK
- Comment interpréter cela ?
- Coeff. de symétrie : mesure la symétrie de la courbe par rapport à la loi normale centrée réduite (Coeff. de symétrie = 0) :
- Coeff. de symétrie < 0
la courbe est tronquée à droite et décalée à gauche
- Coeff. de symétrie > 0
la courbe est tronquée à gauche et décalée à droite
- Coeff. d'aplatissement : mesure l'aplatissement de la courbe par rapport à la loi normale centrée réduite (Coeff. d'aplatissement = 3) :
- Coeff. d'aplatissement < 3
la courbe est plus aplatie que la loi normale centrée réduite
- Coeff. d'aplatissement > 3
la courbe est plus élevée que la loi normale centrée réduite
- La valeur-test : fait référence aux tests statistiques,
si :
- La valeur-test > 2
l'hypothèse nulle "la distribution de la variable est une loi normale centrée réduite" est rejetée au seuil 0,05
(on prend un risque inférieur à 5% en estimant que la variable ne suit pas une loi normale centrée réduite)
Pour en savoir plus sur les tests statistiques, cliquez ici
On utilisera la moyenne et l'écart-type pour décrire une variable quand VT < 2
- Qu'en est-il de la distribution des SUICides ?
- Et pour les autres, s'éloignent-elles significativement de la loi centrée réduite ?
- Sont-elles pour autant proche de cette loi (cf. coef. sym. et applat.) ?
- La régression linéaire
Pour afficher la droite de régression linéaire sur toutes les cellule de la galerie de graphique
- Sélectionner le bouton Régression linéaire
(ou Menu Outils + Régression linéaire)
- Double clique sur les rapports
- Qu'est-ce que le coefficient de variation* (CV) ?
- Qu'est-ce que le coefficient de corrélation* ?
- Double clique sur le graphe
Faire :
- Graphique + Nouveau (Ctrl + N)
- Sélectionner toutes les options
Puis à titre d'exercice
- mettre un nom aux différentes villes
- Menu Sélection + De tous les points
- Menu Habillage + Ecrire les libellés
- relier les villes "géographiquement" proches
- Menu Dessin + Segments
- Le chômage et le suicide sont-ils liés (corrélés) ?
- Y a-t-il une spatialisation du suicide ou du chômage ?
- Les chômeurs se suicident-ils beaucoup ?
Notion d'erreur écologique* pour en savoir sur plus l'EC cliquer ici
NB : les mots suivis de "*" font partie du vocabulaire statistique, donc leur définition doit être connue. Faites-vous un glossaire.