V.2.4 - Dernière mise à jour : 02/01/2022
Très complémentaires des analyses factorielles, dont l'objectif est de faire apparaître des structures, les classifications servent à réaliser des partitions dans la masse des individus.
La classification peut proposer plusieurs partitions hiérarchisées avec un nombre de classes (groupes) différent.
Partitionner la distribution revient à affecter chaque individu à une classe et à une seule,
c'est un moyen très commode pour cartographier les résultats des analyses factorielles.
Ce cours doit beaucoup aux ouvrages suivants : ESCOFIER 2008, NAKACHE 2000, SANDERS 1989
Les techniques de classification sont exploratoires.
Elles servent souvent à formuler des hypothèses de travail.
On peut les opposer aux méthodes de classement, dont le but est plus prédictif , voire explicatif.
Dans la littérature, cinq grands types de méthodes de classification émergent :
Deux méthodes vont être décrites ici, celles proposées dans SPAD et SAS, à savoir :
Déterminer une stratégie de classification en fonction des données.
Les variables peuvent être : continues, ordinales, nominales et binaires.
=> Homogénéisation des données car un seul critère d'agrégation
Données quantitatives => distance
Données qualitatives => indice de similarité
Avec SPAD, deux étapes successives sont proposées :
=> codage des données sous forme disjonctive complète (0/1)
- les qualitatives sont décomposées en modalités ;
- les quantitatives sont discrétisées, puis chaque classe est traitée comme une modalité.
=> une AFC est réalisée sur le tableau disjonctif complet, c'est donc une ACM !
Quelque soit le tableau de données initial, la classifications des individus se fera sur des données quantitatives - les coordonnées des axes factoriels.
En pratique, on ne retient pas tous les axes factoriels dans la classification :
- pour éliminer le "bruit" des derniers axes ;
- pour améliorer l'homogénéité des classes
=> en général, on conserve un peu plus de la moitié des axes.
Remarque : si les données d'origine sont toutes quantitatives ou toutes binaires, il n'est pas nécessaire de les recoder.
Technique fournissant un système de classes emboîtées dont l'hétérogénéité va croissante avec la taille des classes.
On visualise un arbre hiérarchique indicé nommé dendrogramme.
Les éléments terminaux sont appelés les feuilles de l'arbre.
- Comment les regrouper ?
Cette construction nécessite :
- un critère d'agrégation
- une procédure d'agrégation
Dans SPAD, le critère retenu est celui qui assure la perte d'inertie minimale quand on passe d'une partition à la suivante => critère de Ward
formule dfm04fo1
La différence d'inertie entre deux classes h et h' est fonction de :
- mh et mh' les masses respectives de h et h' ;
- gh et gh' les centres de gravité de h et h' ;
- d2(gh , gh') le carré de la distance euclidienne entre les centres de classes gh et gh'
Ce critère représente le moment d'inertie* de l'ensemble des deux points gh et gh' munis de leur masse respective mh et mh' que l'on compare à leur centre de gravité g.
formule dfm04fo2
Le critère de Ward fournit des classes sphériques.
Par construction d'une matrice de perte d'inertie.
Comme on recherche des classes les plus différentes entre elles. Cela se traduit par une :
C'est l'inertie intra-classes minimale qui va être favorisée dans les étapes suivantes.
Comme cela est fort bien expliqué sur le site de Joseph Larmarange :
"Le principe de la CAH est de rassembler des individus selon un critère de ressemblance défini au préalable qui s’exprimera sous la forme d’une matrice de distances, exprimant la distance existant entre chaque individu pris deux à deux. Deux observations identiques auront une distance nulle. Plus les deux observations seront dissemblables, plus la distance sera importante. La CAH va ensuite rassembler les individus de manière itérative afin de produire un dendrogramme ou arbre de classification. La classification est ascendante car elle part des observations individuelles ; elle est hiérarchique car elle produit des classes ou groupes de plus en plus vastes, incluant des sous-groupes en leur sein. En découpant cet arbre à une certaine hauteur choisie, on produira la partition désirée." in : http://larmarange.github.io/analyse-R/classification-ascendante-hierarchique.html
Le principe est de tirer aléatoirement des points qui deviennent de ce fait des centres !
Puis :
tirage d'un nouveau point, agrégé au centre le plus proche ;
calcul du nouveau centroïde (par la moyenne, la médiane...) ;
tirage d'un nouveau point ;
etc.
Sources : L. Lebart, A. Morineau, M. Piron, 2006 « Statistique exploratoire multidimensionnelle », Collection : Sciences Sup, Dunod, 4ème éd., 480 p.
De nombreuses familles de partitions existent. Elles visent toutes à minimiser la variance intra-groupe et à maximiser la distance entre les centroïdes des groupes.
En anglais, on parle de "partitional clustering" (ou "partitioning clustering").
Il faut spécifier le nombre de classes attendu.
Parmi ces méthodes (in : Partitional Clustering in R: The Essentials) :

La classification présentée ici fait suite à une analyse en composantes principales (ACP). Les données issues du tableau 4.1 (exemple n°1) sont transformées. La métrique utilisée est euclidienne.
Tableau 4.1 - La structure pastorale éthiopienne par
awrajas (en nombre de têtes), [Sources : EASTMAN
(J.R.) - 1997 - 10. Database Workshop. in : IDRISI for Windows.
Tutorial Exercises. Version 2.0. Worcester (MA, USA), Clark University,
pp. 69-79 et traduction française GODARD,
2003]
Ce fichier est au format Excel (.xls) et "pèse" 51 Ko.
Pour un traitement avec R :
Téléchargement du fichier de données CSV (dfm04ta1.csv)
Ce fichier est au format CSV et "pèse" 11 Ko.
Téléchargement du script CAH_awrajas_v3.RPour la cartographie de l'analyse :
- sous ArcGis, récupérer le fichier de formes (shp) et sa base de données dans le dfm04ta1_ag.rar.
Ce fichier est compressé (.rar) et "pèse" 68 Ko.
Ce tableau est le support d'un exercice détaillé sur la fiche guide 1.8 du cours de SIG.
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Variables
- Sélection des variables : Continues actives
=> toutes sauf population
- Sélection des variables : Continues illustratives
=> population
Onglet Individus
- Choix des individus
=> tous
Onglet Pondération
=> Uniforme
Onglet Paramètres
- Paramètres de fonctionnement :
Analyse normée (synonyme de standardisée*)
Coordonnées conservées toutes
- Paramètres d'édition :
Matrice permutée selon F1 Non
Coordonnées éditées toutes
Résultats pour les individus tous
Nombre de décimales 2
- Fichier pour application tableur : Oui
Options pour application tableur :
Résultats pour les individus Oui
Édition pour la matrice analysée Identifiant long
- Valider par OK deux fois
- Méthode + Exécuter méthode (ou Shift + F5)
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Commande de description
- Liste des axes à décrire : 1-3
- Avec les éléments :
Variables continues Actives seules
Individus Actifs seuls
Onglet Paramètres
Laisser Défaut
- Méthode + Exécuter méthode (ou Shift + F5)
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Paramètres
- Choix de la méthode : Hiérarchique (RECIP)
La méthode SEMIS est une méthode mixte pour classer les très grands nombres d'individus.
- Paramètres de fonctionnement :
Coordonnées utilisées pour l'agrégation : Toutes
Sauvegarde partielle de l'arbre (nombre d'éléments terminaux) : 50
- Paramètres d'édition :
Histogramme des indices : 50
Composition des éléments terminaux : Oui
Coordonnées des éléments terminaux : Toutes
Caractéristiques des nœuds : Oui
Dendrogramme (arbre hiérarchique) : Large
- Méthode + Exécuter méthode (ou Shift + F5)
- Méthode + Paramètres ... (ou Shift + F6)
Onglet Choix des partitions
- Recherche automatique des meilleurs partitions :
Nombre de partitions : 3
Nombre minimum de classes par partition : 2
Nombre maximum de classes par partition : 6
Onglet Paramètres de partitionnement
- Paramètres de partitionnement :
Itérations de consolidation : 10
Affectation des individus illustratifs aux classes les plus proches : Oui
- Paramètres d'édition : par défaut
Onglet Caractérisation des partitions
=> par défaut
- Méthode + Exécuter méthode (ou Shift + F5)
- Enregistrement et exécution de la filière
- Filière + Enregistrer filière sous ...
D:\geo\Votre_nom\fm18\copri-recip1.fil
Donner un titre "causant", car il apparaîtra sur le bandeau de la fenêtre
- Filière + Exécuter filière (ou F5)
La classification présentée ici fait suite à une analyse factorielle des correspondances binaires (AFC). Les données issues du tableau 4.2 (exemple n°2) ne sont pas transformées comme pour l'exemple n°1, car la métrique utilisée est celle du Khi2.
Reprendre le Tableau 4.1 - La structure pastorale
éthiopienne par awrajas (en nombre de têtes), [Sources : EASTMAN
(J.R.) - 1997 - 10. Database Workshop. in : IDRISI for Windows.
Tutorial Exercises. Version 2.0. Worcester (MA, USA), Clark University,
pp. 69-79 et traduction française GODARD,
2003]
Ce fichier est au format Excel (.xls) et "pèse" 51 Ko.
Ce tableau est le support d'un exercice détaillé sur la fiche guide 1.8 du cours de SIG.
Pour la cartographie de l'analyse :
- sous ArcGis, récupérer le fichier de formes (shp) et sa base de données dans le dfm04ta1_ag.rar.
Ce fichier est compressé (.rar) et "pèse" 68 Ko.
Ce tableau est le support d'un exercice détaillé sur la fiche guide 1.8 du cours de SIG.
La description proposée correspond à une coupure (partition) de l'arbre de la CAH en 4 classes intitulée "Coupure 'b' de l'arbre en 4 classes". C'est l'onglet DECLA-10.
tab. 4.2a - Classe 1 / 4 - Caractérisation par les fréquences des classes de la partition (onglet DECLA-10)
Fréquences caractéristiques % de la fréquence dans l'échantillon GLOBAL % de la fréquence dans la classe FRE / CLA % de la classe dans la fréquence CLA / FRE Valeur-Test Probabilité Poids écarts au GLOBAL cattle 63.84
67.91
32.21
318.39
0.000
20561700
6%
sheep 22.04
24.29
33.37
201.82
0.000
7099180
10%
goats 14.11
7.79
16.72
-712.03
0.000
4545520
- 45%
100.00
100.00
tab. 4.2b - Classe 2/ 4 - Caractérisation par les fréquences des classes de la partition (onglet DECLA-10)
Fréquences caractéristiques % de la fréquence dans l'échantillon GLOBAL % de la fréquence dans la classe FRE / CLA % de la classe dans la fréquence CLA / FRE Valeur-Test Probabilité Poids écarts au GLOBAL cattle 63.84
78.93
48.33
1456.83
0.000
20561700
24%
goats 14.11
11.92
33.01
-289.76
0.000
4545520
-16%
sheep 22.04
9.16
16.25
-1481.85
0.000
7099180
-58%
100.00
100.00
Comment lire les en-têtes de colonnes (qui s'appellent des FREQUENCES dans un tableau de contingence chez SPAD !) ?
On trouvera un descriptif pour permettre la compréhension de ces tableaux de classification dans NAKACHE 2000 pp. 61-65.
Ont été rajoutés en GRAS les en-têtes tels qu'ils sont présentés dans le listage (Editeur de résultats de SPAD 7 et antérieur).
% de la fréquence dans l'échantillon - GLOBAL : représente la part en pourcentage de sujets (cattle, goats, sheep) dans l'échantillon global (l'ensemble des animaux pour toutes les Awrajas).
Il y a pour 100 % des animaux éthiopiens : 63,84 % de bovidés (cattle) ; 14.11 % de caprins (goats) et 22,04 % d'ovins (sheep).
% de la fréquence dans la classe - FRE / CLA : représente le pourcentage de chaque catégorie d'animaux (cattle, goats, sheep) dans la classe.
Il y a dans la classe 1 (tableau 4.2a) pour 100 % de ses animaux : 67.91 % de bovidés (cattle) ; 24.29 % de caprins (goats) et 7,79 % d'ovins (sheep). Par rapport au GLOBAL (moyenne générale), les écarts sont de :
- pour les bovidés, une sur représentation de 4 points [(67,91-63,84), soit 6 % de la valeur de la moyenne générale obtenue par (67,91-63,84) / 63,84] ;
- pour les caprins, une sur représentation de 2,3 points [(24,29-22,04), soit 10 % de la valeur de la moyenne générale obtenue par (24,29-22,04) / 22,04] ;
- pour les ovins, une sous représentation de 6,3 points [(7,79-14,11), soit - 45 % de la valeur de la moyenne générale obtenue par (7,79-14,11) / 14,11] ;
% de la classe dans la fréquence - CLA / FRE : représente le pourcentage de chaque catégorie d'animaux (cattle, goats, sheep) dans la classe par rapport à l'échantillon global (la population des animaux).
Il y a dans la classe 1 (tableau 4.2a) : 32,21 % de l'ensemble des bovidés (cattle), les autres sont pour 48,33 % dans la classe 2 (tableau 4.2b), 14,34 % dans la classe 3 (tableau non affiché) et 5,12 % dans la classe 4 (tableau non affiché). Soit un total de 100 % de bovidés.
Procédez pareillement pour les ovins et les caprins (goats)
Qu'est-ce qui différencie la classe 1 de la classe 2 ?
- La classe 1 (tableau 4.2a) sur représente les bovidés (+ 6 % par rapport à la moyenne) et les ovins (+ 10 % par rapport à la moyenne) alors que les caprins y sont sous représentés (- 45 % par rapport à la moyenne) ;
a contrario,
- La classe 2 (tableau 4.2b) continue de sur représenter les bovidés, mais plus fortement (+ 24 % par rapport à la moyenne), alors que les ovins sont cette fois-ci sous représentés et fortement (- 58 % par rapport à la moyenne) avec les caprins, un peu plus faiblement que dans la classe 1 (- 16 % par rapport à la moyenne).
La classification présentée ici fait suite à une analyse factorielle des correspondances multiples (ACM). Les données issues du tableau 4.3 (exemple n°3).
Tableau 4.3 - Dossier Départemental des Risques Majeurs -
Information des populations, [Sources : Ministère de
l'aménagement du territoire et de l'environnement, Préfecture de l'Aude,
2001]
Codage en 2 classes (oui - non)
Ce fichier est au format Excel (.xls) et "pèse" 763 Ko.
Codage en 4 classes (absence 0 ; non concerné 1 ; aléa sans enjeu 2 ; aléa avec enjeu ou enjeu humain à l'étude 3)
Ce fichier est au format Excel (.xls) et "pèse" 763 Ko.
La description proposée correspond à une coupure (partition) de l'arbre de la CAH en 3 classes intitulée "Coupure 'a' de l'arbre en 3 classes". ici, en fonction des paramétrages retenus dans SPAD, c'est l'onglet DECLA-5 qui contient l'information présentée.
tab. 4.3a - Classe 1 / 3 - Caractérisation par les modalités des classes de la partition (Effectif: 227 - Pourcentage: 62.88 ; onglet DECLA-5)
Libellés des variables Modalités caractéristiques % de la modalité dans la classe MOD / CLA % de la modalité dans l'échantillon GLOBAL % de la classe dans la modalité CLA / MOD Valeur-Test Probabilité Poids écarts au GLOBAL Séisme 1 100.00
66.48
94.58
19.12
0.000
240
50%
Rupt_barrage 1 98.68
92.24
67.27
5.77
0.000
333
7%
Inondation 2 70.48
60.11
73.73
5.12
0.000
217
17%
Transp_mat_dang 2 41.85
33.24
79.17
4.51
0.000
120
26%
Risq_indust 1 100.00
97.78
64.31
3.42
0.000
353
2%
Mouv_terrain 1 99.12
96.95
64.29
2.76
0.003
350
2%
Mouv_terrain 2 0.88
3.05
18.18
-2.76
0.003
11
-71%
Risq_indust 2 0.00
2.22
0.00
-3.42
0.000
8
-100%
Transp_mat_dang 1 58.15
66.76
54.77
-4.51
0.000
241
-13%
Inondation 1 29.52
39.89
46.53
-5.12
0.000
144
-26%
Rupt_barrage 2 1.32
7.76
10.71
-5.77
0.000
28
-83%
Séisme 2 0.00
33.52
0.00
-19.12
0.000
121
-100%
tab. 4.3b - Classe 2 / 3 - Caractérisation par les modalités des classes de la partition (Effectif: 8 - Pourcentage: 2.22 ; onglet DECLA-5)
Libellés des variables Modalités caractéristiques % de la modalité dans la classe MOD / CLA % de la modalité dans l'échantillon GLOBAL % de la classe dans la modalité CLA / MOD Valeur-Test Probabilité Poids écarts au GLOBAL Risq_indust 2 100.00
2.22
100.00
8.17
0.000
8
4412%
Transp_mat_dang 2 100.00
33.24
6.67
3.66
0.000
120
201%
Inondation 2 100.00
60.11
3.69
2.14
0.016
217
66%
Inondation 1 0.00
39.89
0.00
-2.14
0.016
144
-100%
Transp_mat_dang 1 0.00
66.76
0.00
-3.66
0.000
241
-100%
Risq_indust 1 0.00
97.78
0.00
-8.17
0.000
353
-100%
tab. 4.3c - Classe 3 / 3 - Caractérisation par les modalités des classes de la partition (Effectif: 126 - Pourcentage: 34.90 ; onglet DECLA-5)
Libellés des variables Modalités caractéristiques % de la modalité dans la classe MOD / CLA % de la modalité dans l'échantillon GLOBAL % de la classe dans la modalité CLA / MOD Valeur-Test Probabilité Poids écarts au GLOBAL Séisme 2 93.65
33.52
97.52
19.01
0.000
121
179%
Transp_mat_dang 1 86.51
66.76
45.23
5.96
0.000
241
30%
Inondation 1 61.11
39.89
53.47
5.91
0.000
144
53%
Rupt_barrage 2 18.25
7.76
82.14
5.15
0.000
28
135%
Mouv_terrain 2 6.35
3.05
72.73
2.29
0.011
11
108%
Mouv_terrain 1 93.65
96.95
33.71
-2.29
0.011
350
-3%
Rupt_barrage 1 81.75
92.24
30.93
-5.15
0.000
333
-11%
Inondation 2 38.89
60.11
22.58
-5.91
0.000
217
-35%
Transp_mat_dang 2 13.49
33.24
14.17
-5.96
0.000
120
-59%
Séisme 1 6.35
66.48
3.33
-19.01
0.000
240
-90%
Comment lire les en-têtes de colonnes (qui s'appellent des MODALITÉS dans un tableau de contingence chez SPAD !) ?
On trouvera un descriptif pour permettre la compréhension de ces tableaux de classification dans NAKACHE 2000 pp. 61-65.
Ont été rajoutés en GRAS les en-têtes tels qu'ils sont présentés dans le listage (Editeur de résultats de SPAD 7 et antérieur).
La modalité caractéristique est codée :
- % de la modalité dans l'échantillon - GLOBAL : représente la part en pourcentage des communes qui (tableau 4.3a) :
- présentent le risque d'Inondation (Modalités caractéristiques = 2 ; 60,11 %) ;
- ne le présentent pas (Modalités caractéristiques = 1 ; 39,89 %).
ou
- présentent le risque de Transp_mat_dang (Modalités caractéristiques = 2 ; 33,24 %) ;
- ne le présentent pas (Modalités caractéristiques = 1 ; 66,76 %).
dans l'échantillon global (pour toutes les communes).
- % de la modalité dans la classe - MOD / CLA : représente le pourcentage de sujets de la classe par modalité.
Dans la tableau 4.3a,
- l'absence de séismes (codé 1) est manifeste. Le pourcentage de la modalité dans la classe est de 100 %. pour le codage en "1" et de 0 % pour le codage en "0" ;
- en revanche, le Transp_mat_dang est minoritaire pour qualifier cette classe. Seul 41,85 % des communes de cette classe courent ce risque (codage 2), alors que 58,15 % (codage 1) ne le courent pas. Par rapport au GLOBAL (moyenne générale), les écarts sont de :
- pour les séismes (codé 1, donc non-séisme !), il y a sur représentation de 43,52 points [(100-66,48), soit 50 % de la valeur de la moyenne générale obtenue par (100-66,48) / 66,48] pour l'absence de séisme;
- pour les inondations (codé 2), il y a sur représentation de 10.37 points [(70,48-60,11), soit 17 % de la valeur de la moyenne générale obtenue par (70,48-60,11) / 60,11] ;
- pour les Risq_indust (codé 2), il y a sous représentation de 2,22 points [(0-2,22), soit - 100 % de la valeur de la moyenne générale obtenue par (0-2,22) / 2,22] ; donc il n'y a pas dans cette classe de risques industriels.
- % de la classe dans la modalité - CLA / MOD : représente le pourcentage de sujets présentant la modalité (codée 1 ou 2) et appartenant à la classe.
- si 54,77 % de l'ensemble des communes non concernées par le Transp_mat_dang (codage 1) se trouve dans la classe 1 (tableau 4.3a), 0 % se trouve dans la classe 2 (tableau 4.3b) et 45.23 % dans la classe 3 (tableau 4.3c) ;
- en revanche, s'il n'y a pas de communes présentant des risques industriels dans classe 1 (tableau 4.3a), elles se trouvent toutes (100 %) dans la classe 2 (tableau 4.3b). On n'en trouve pas dans la classe 3 (pas de 0 %, tableau 4.3c), car la Valeur-Test est sans doute inférieure à 2, donc non significative.
Qu'est-ce qui différencie la classe 1 de la classe 2 ?
- La classe 1 (tableau 4.3a) sur représente les communes risquant les inondations (codage 2, + 17 % par rapport à la moyenne) et celles qui concentrent le Transp_mat_dang (codage 2, + 26 % par rapport à la moyenne) alors que celles qui redoutent les séismes y sont sous représentées (codage 2, - 100 % par rapport à la moyenne), etc. ;
a contrario,
- La classe 2 (tableau 4.3b) concentre les communes sur représentant le Risq_indust [codé 2, 4412 % !, soit presque 45 fois plus (8 communes avec le codage 2, contre 353 avec le codage 1 ) de concentration de ce risque dans cette classe que dans l'ensemble du département. C'est normale, elles y sont toutes regroupées. Cette classe est encore plus fortement impliquée dans le Transp_mat_dang (codage 2, + 201 % par rapport à la moyenne) que la classe 1 (tableau 4.3a)... C'est la seule qui sur représente les modalités en code "2" qui la concernent et sous représente les modalités en code "1" qui sont d'ailleurs les même, mais à - 100 %.
Qu'en est-il des feux de forêt ?
Quel nom (titre) donneriez-vous à ces classes en fonction des modalités qui les caractérisent ?
La classification présentée ici fait suite à une analyse factorielle des correspondances binaires (AFC). Les données issues du tableau ci-dessous ne sont pas transformées comme pour l'exemple n°9 de l'ACP, car la métrique utilisée est celle du Khi2.
Exemple n°4.4 : La propriété forestière en France
Accéder aux données
Téléchargement du fichier (cf. détails sur la plateforme Moodle à la rubrique La propriété forestière française en 2007)
Le fond cartographique des limites administratives en 90 ou 96 départements [l'Île-de-France, pour les données forestières, a été regroupée en ÎdF ouest, 75+78+91+92+93+94+95). La Seine-et-Marne est restée indépendante] est accessible ici : http://julienas.ipt.univ-paris8.fr/vgodard/pub/enseigne/carto2/claroline/tdfm32/depart_90_96.rar
Téléchargement du résumé du script généré en R Markdown :
- AFC_propfor_v2.html (en html) ;
- AFC_propfor_v2.Rmd (en R Markdown)
Affichage de l'aide à l'analyse Investigate(res.propfor.ca) inclus dans le R Markdown ci-dessus (vous remarquerez que le module Investigate n'apporte pas grand chose dans la partie classification, voire a "bogué" ! Fiez-vous plutôt à vos connaissances^^).
Accéder au fichier élaboré des résultats des classifications (description des classes de la partition par les variables)
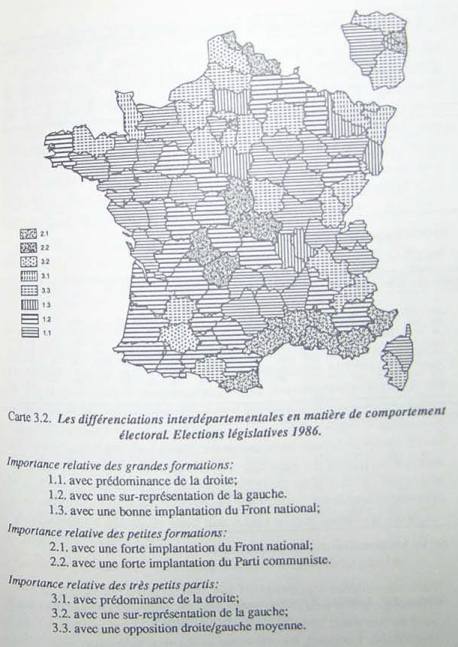
fig. 2 - Une possibilité de légende pour la cartographie d'une typologie (avec emboîtement par numérotation)
sources : SANDERS 1989, p. 213
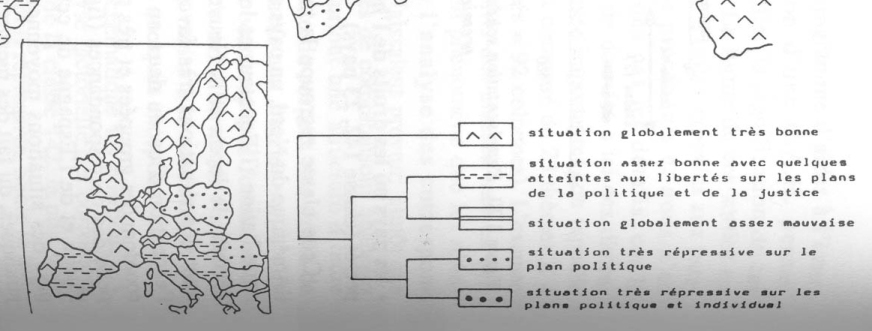
fig. 3 - Une possibilité de légende pour la cartographie d'une typologie (avec emboîtement graphique)
sources : SANDERS 1989, p. 222
NB : les mots suivis de "*" font partie du vocabulaire statistique, donc leur définition doit être connue. Faites-vous un glossaire.